Como a Microsoft otimiza automaticamente milhões de bancos de dados

Mostrar/Ocultar
Introdução
Durante muito tempo, tuning de banco de dados foi uma atividade essencialmente manual: analisar consultas, ajustar índices, acompanhar fragmentação e manter rotinas periódicas de manutenção.
Com o Automatic Tuning do Azure SQL Database lançado e aprimorado a partir de 2016, esse modelo evoluiu para um sistema que observa continuamente o padrão de consultas, aplica otimizações e valida automaticamente o impacto dessas mudanças.
Em 2026, com a introdução da compactação automática de índices, até mesmo a manutenção deles passa a ser tratada como um processo contínuo dentro do próprio mecanismo de inteligência do banco de dados.
O Automatic Tuning da Microsoft
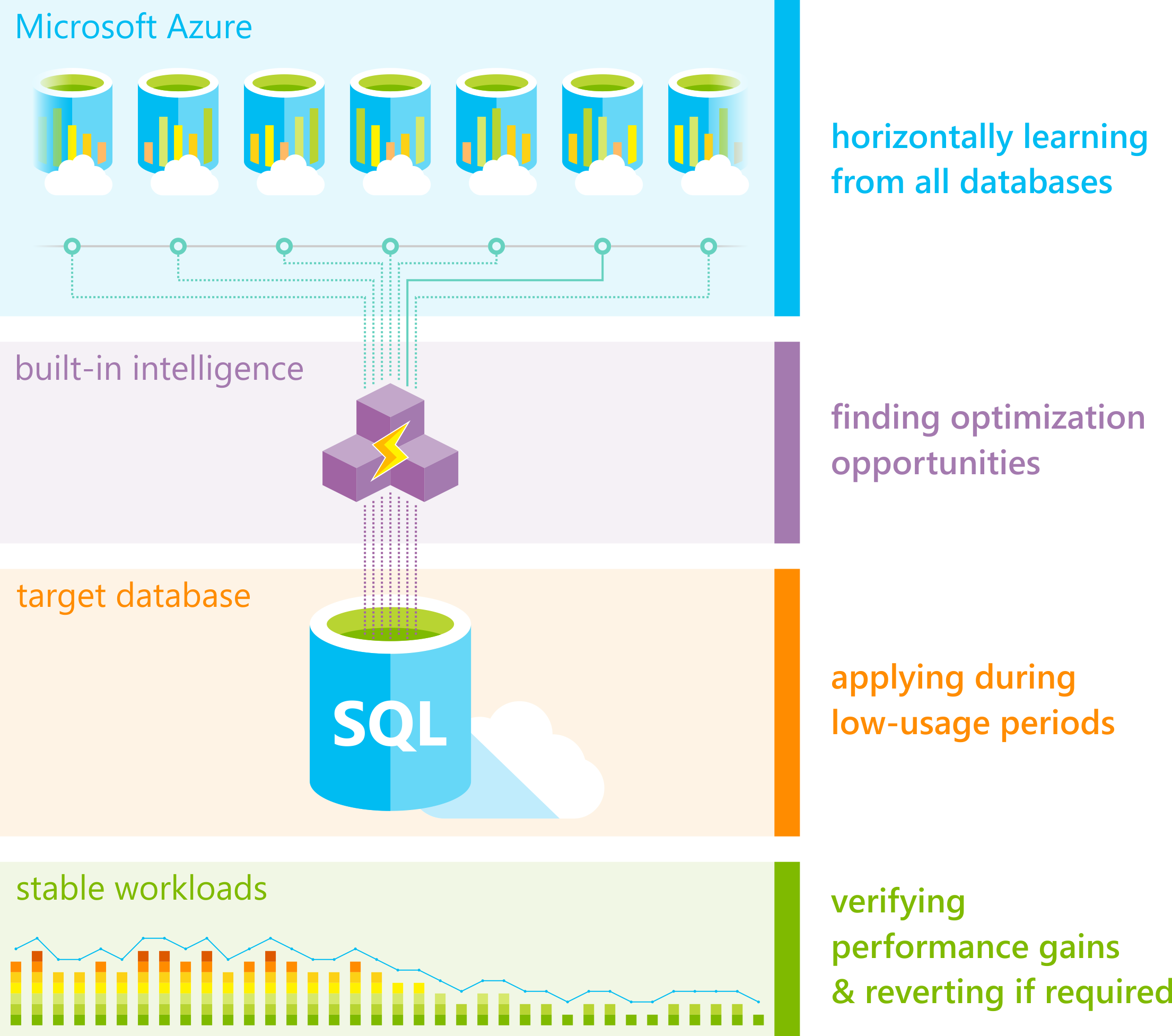
O Automatic Tuning utiliza dados reais de execução de consultas para tomar decisões. A base disso é o Query Store, que armazena histórico de planos de execução, métricas de desempenho e padrões de uso.
Segundo a documentação oficial e o paper da Microsoft Research, o sistema:
- Analisa continuamente consultas executadas em produção.
- Identifica padrões de acesso a dados e gargalos de performance.
- Gera recomendações de criação e remoção de índices.
- Aplica essas recomendações automaticamente quando habilitado.
- Valida cada alteração com base em impacto.
Arquitetura e funcionamento interno
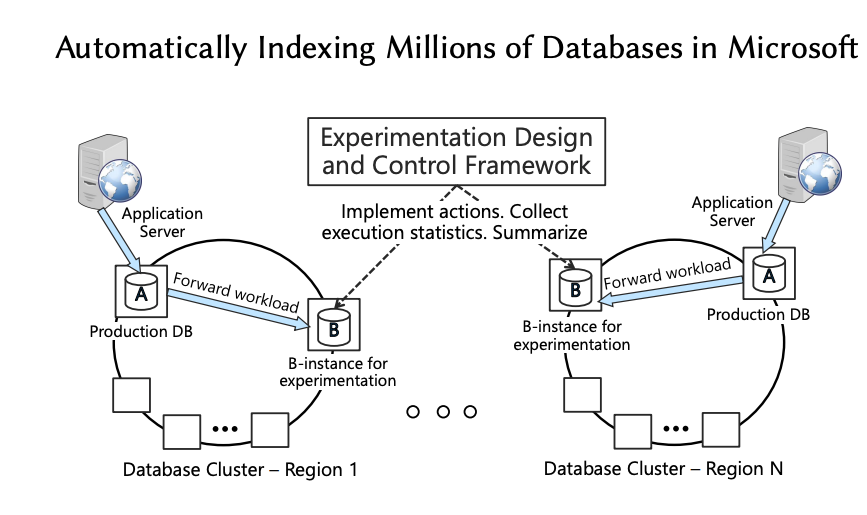
De acordo com o paper “Automatically Indexing Millions of Databases in Microsoft Azure SQL Database”, o sistema é construído como um conjunto de serviços distribuídos.
Cada banco possui um ciclo de otimização com etapas bem definidas:
- Análise das consultas armazenadas no Query Store.
- Geração de recomendações de índices.
- Aplicação automática das mudanças.
- Validação do impacto real em produção.
- Reversão automática em caso de regressão.
Os componentes principais são:
- Analisador: Processa dados de execução e identifica oportunidades.
- Recomendador: Utiliza heurísticas como missing indexes e evolução do Database Engine Tuning Advisor (DTA).
- Executor: Aplica CREATE/DROP INDEX ou força planos.
- Validador: Compara desempenho antes e depois da mudança.
Esses serviços operam de forma assíncrona e com baixa prioridade de recursos, permitindo escalar para milhões de bancos sem impacto relevante.
Ciclo de decisão e segurança
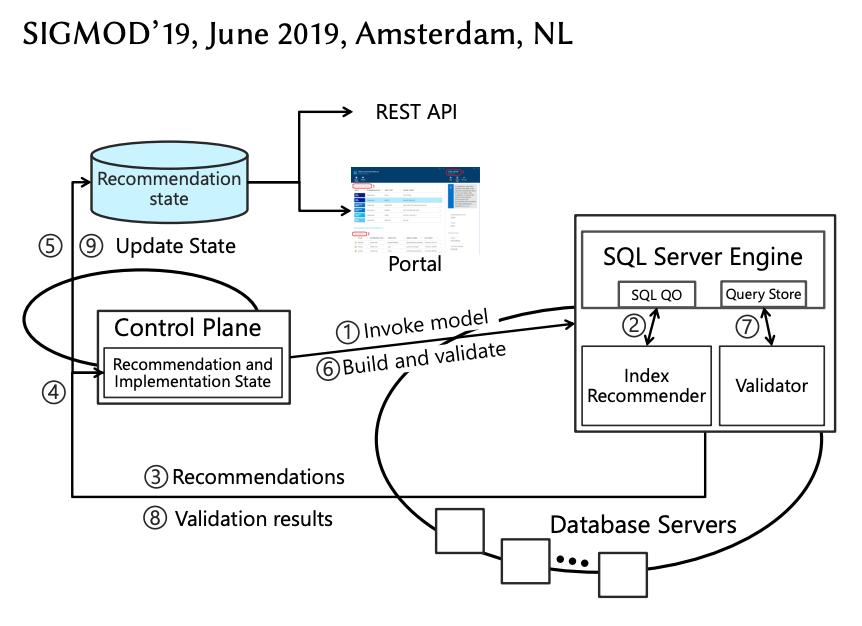
Um dos pontos mais importantes é o modelo de validação.
Toda mudança segue o mesmo fluxo:
- Identificação de uma possível melhoria.
- Aplicação controlada da alteração.
- Monitoramento do impacto em execução real.
- Reversão automática caso não haja ganho.
Segundo a Microsoft, esse modelo permite aplicar tuning diretamente em produção com segurança, já que regressões são detectadas e corrigidas automaticamente.
Esse mecanismo resolve um problema clássico do tuning manual: decisões baseadas em amostras limitadas ou ambientes de teste pouco representativos.
Criação e remoção automática de índices

A criação automática de índices é baseada na observação de consultas reais.
O sistema identifica padrões de acesso onde um índice poderia reduzir custo de execução, especialmente em operações de leitura.
O processo funciona assim:
- O índice é criado automaticamente.
- O desempenho das consultas relacionadas é monitorado.
- O índice é mantido apenas se houver ganho consistente.
Da mesma forma, índices não utilizados ou com baixo impacto são candidatos à remoção.
Esse processo contínuo evita tanto a ausência de índices quanto o acúmulo excessivo, que normalmente impacta operações de escrita.
Correção no plano de execução das queries
Mudanças de plano de execução podem causar degradações inesperadas.
Isso pode acontecer por:
- Atualização de estatísticas.
- Mudança de distribuição de dados.
- Sensibilidade a parâmetros.
O Automatic Tuning monitora consultas e identifica quando um plano piora.
Nesses casos, ele pode:
- Forçar o uso do último plano conhecido como o melhor.
- Monitorar continuamente o impacto.
- Reverter a decisão caso o cenário mude.
Esse mecanismo reduz a necessidade de intervenção manual em incidentes de performance.
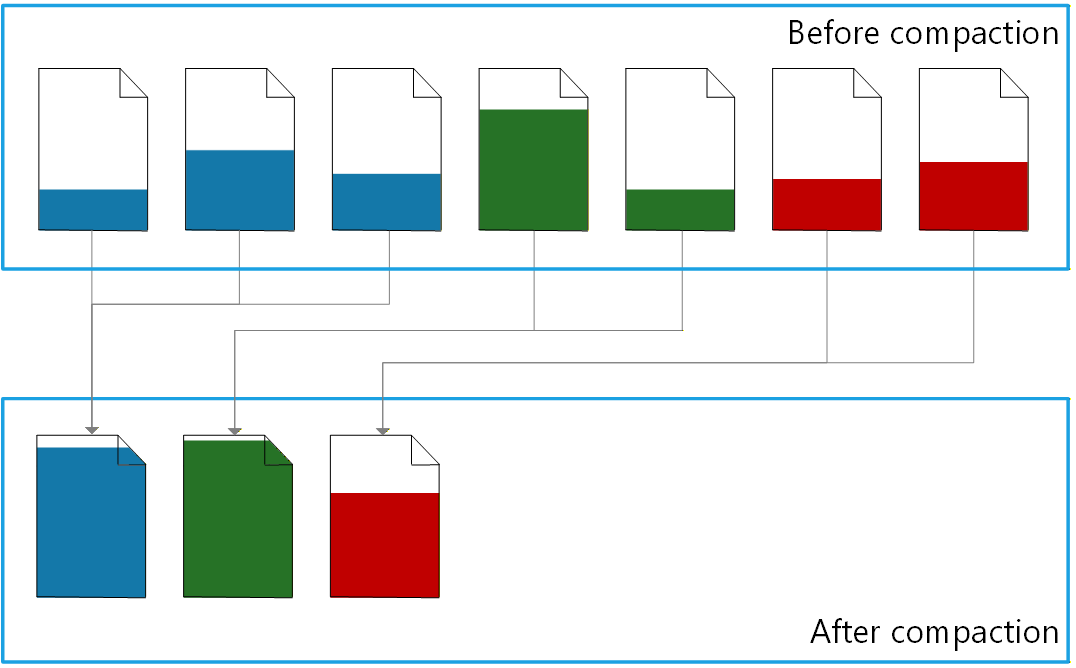
Compactação automática de índices (2026)
A compactação automática de índices, anunciada em 2026, atua diretamente na estrutura dos índices.
O problema que ela resolve é comum em sistemas OLTP: com inserções, atualizações e deleções, os índices passam a ocupar mais páginas do que o necessário.
Tradicionalmente, isso era resolvido com:
- REORGANIZE.
- REBUILD.
- Monitoramento manual de fragmentação.
Essas operações têm custo computacional elevado e precisam ser agendadas.
A compactação automática muda essa abordagem.
Funcionamento da compactação
Segundo o anúncio oficial da Microsoft, a compactação:
- Atua continuamente em background.
- Consolida páginas parcialmente preenchidas.
- Move registros entre páginas.
- Libera páginas vazias.
Isso reduz overhead e evita necessidade de processos dedicados de alto custo.
Impacto técnico
A compactação automática melhora diretamente a eficiência dos índices:
- Reduz o número de páginas.
- Aumenta a densidade de página.
- Diminui leituras lógicas.
- Reduz uso de CPU e memória.
Segundo experimento oficial da Microsoft (carga OLTP simulada):
| Métrica | Antes do teste | Após do teste | Após a compactação automática |
|---|---|---|---|
| Leituras lógicas | 25 | 1.610 | 35 |
| Densidade (%) | 99,51% | 52,71% | 96,11% |
| Páginas | 962 | 4.394 | 1.065 |
Interpretação:
- Escritas intensas degradam rapidamente o índice (page splits + espaço vazio).
- A compactação automática recupera quase todo o estado original.
- Reduz ~98% das leituras após degradação.
Acontecendo automaticamente, em background e sem rebuild manual.
Papel do DBA e da aplicação
Com esse nível de automação, existe uma mudança clara de responsabilidade entre aplicação e banco.
A aplicação precisa focar em dois pontos principais:
- Modelagem de dados adequada.
- Forma de acesso às informações (queries eficientes, padrões consistentes).
O banco, por outro lado, passa a otimizar a execução dessas consultas ao longo do tempo.
O Automatic Tuning não corrige problemas estruturais. Ele parte do princípio de que o modelo e as queries fazem sentido, e então otimiza em cima disso.
Fine tuning manual está perdendo espaço
Historicamente, ambientes críticos eram altamente ajustados manualmente. Índices eram criados com base em queries específicas e mantidos ao longo do tempo.
Esse modelo começa a perder espaço porque:
- Aplicações mudam com frequência.
- Novas funcionalidades alteram padrões de acesso.
- Queries deixam de ser estáticas.
- O comportamento do sistema evolui constantemente.
Um índice ideal hoje pode deixar de ser relevante rapidamente.
Manter um banco 100% ajustado manualmente nesse cenário gera custo alto e pouco retorno.
O novo equilíbrio
Com o Automatic Tuning, o banco passa a se ajustar continuamente com base no uso real.
Isso muda o objetivo:
- Não se busca mais um estado perfeito e estático.
- O foco passa a ser adaptação contínua.
Na prática:
- Índices são criados e removidos conforme necessidade.
- Planos são corrigidos automaticamente.
- Estrutura física é ajustada continuamente.
Um banco “bom o suficiente” e adaptativo tende a performar melhor ao longo do tempo do que um banco rigidamente otimizado para um cenário específico.
O DBA continua agregando valor
Mesmo com automação, o DBA continua sendo relevante em cenários como:
- Workloads muito específicos.
- Sistemas com requisitos de latência extrema.
- Revisão de modelagem de dados.
- Auditoria de decisões automáticas.
O papel passa a ser mais estratégico:
- Definir limites.
- Monitorar comportamento.
- Intervir quando necessário.
Trade-offs
A automação resolve grande parte dos problemas operacionais, mas existem compromissos.
Vantagens:
- Redução de esforço manual.
- Ajustes contínuos baseados em uso real.
- Aprendizado em escala.
- Validação automática com rollback.
Pontos de atenção:
- Menor controle direto sobre decisões específicas.
- Alterações podem ocorrer sem intervenção explícita.
- Pode não atender cenários altamente customizados.
Segundo a Microsoft, o sistema foi projetado para priorizar segurança, revertendo automaticamente alterações que não geram ganho.
Minha experiência com o Automatic Tuning
Na prática, já utilizei o Automatic Tuning em diferentes cenários, desde bancos com poucos gigabytes até ambientes com múltiplos terabytes de dados, incluindo Azure SQL Database e Azure SQL Elastic Pools.
De forma geral, a tecnologia funciona bem e entrega ganhos reais sem necessidade de intervenção constante, principalmente em cenários com padrão de acesso relativamente estável.
Alguns pontos importantes baseados na experiência:
- Em ambientes críticos com exigência de latência, é necessário aplicar com cautela.
- Mudanças automáticas (principalmente criação/remoção de índices) podem gerar variações temporárias de desempenho.
- Mesmo com validação automática e rollback, pode existir impacto durante o período de teste da otimização.
Ainda assim:
- Já apliquei Automatic Tuning em produção com impacto controlado.
- Em geral, após os primeiros dias de adaptação, o ambiente tende a estabilizar com melhorias consistentes.
- O mecanismo de rollback automático reduz significativamente o risco operacional.
Para sistemas menos críticos, a adoção é mais direta:
- Pode ser habilitado com maior segurança.
- O ganho operacional (menos tuning manual) costuma compensar rapidamente.
- Reduz esforço contínuo de manutenção de índices e planos.
Um ponto chave é que o resultado depende fortemente de como a aplicação acessa os dados:
- Queries mal estruturadas continuam sendo um problema.
- Modelagem inadequada não é corrigida automaticamente.
- Padrões de acesso muito voláteis podem reduzir a efetividade das otimizações.
Em resumo, o Automatic Tuning não substitui boas práticas de modelagem e acesso a dados, mas funciona muito bem como um mecanismo de ajuste contínuo em cima de uma modelo de dados saudável.
Comparação com outras soluções
A Microsoft não é a única investindo em tuning automático.
Outros bancos gerenciados em cloud seguem caminhos semelhantes:
- Oracle Autonomous Database: Auto-indexing e proposta de banco autônomo (self-driving database), com forte automação.
- Azure Database for PostgreSQL (Autonomous Tuning): Possui recursos de tuning que analisam consultas e recomendam otimizações.
- Amazon Aurora / RDS: Possui recomendações automáticas via Performance Insights.
O diferencial do Azure SQL está na combinação de aplicação automática, validação em produção com rollback e aprendizado em escala.
Conclusão
O Automatic Tuning do Azure SQL representa uma mudança significativa na forma de otimizar bancos de dados e está em constante evolução.
A capacidade de analisar milhões de bancos, aprender com padrões globais e aplicar melhorias automaticamente reduz a necessidade de tuning manual.
A compactação automática de índices, introduzida em 2026, complementa esse modelo ao tratar continuamente a estrutura física dos índices.
Na prática, o banco deixa de ser um sistema que precisa ser constantemente ajustado manualmente e passa a ser um sistema que se adapta ao uso contínuo.
Referências
- Overview: Automatic Tuning in Azure SQL - Microsoft Learn
- Automatically Indexing Millions of Databases in Microsoft Azure SQL Database - Microsoft Research
- Automatic Tuning Will Be a New Default - Azure Blog
- Autoindexing in Azure SQL Database (PDF) - Microsoft Research
- Stop Defragmenting and Start Living: Introducing Auto-Index Compaction - Tech Community
Conecte-se para transformar sua tecnologia!
Saiba mais e entre em contato: