Desafio de Performance - Rinha de Backend 2026 - Insights da Minha Versão em C# AOT + Similarity Search em Python com FAISS

Mostrar/Ocultar
Introdução
A edição 2026 da Rinha de Backend alterou profundamente o tipo de problema que precisava ser resolvido. Nas edições anteriores, o centro da discussão normalmente girava em torno de concorrência, coordenação entre processos, filas, cache, persistência e throughput HTTP sob carga. Eram desafios clássicos de sistemas distribuídos e engenharia de backend: como aceitar muitas requisições, como evitar contenção, como reduzir latência em operações de I/O e como manter estabilidade quando a pressão de tráfego aumentava.
Em 2026, esses aspectos continuaram relevantes, mas o ponto central passou a ser busca vetorial em tempo real sobre 3 milhões de vetores, operando dentro de um orçamento extremamente agressivo de infraestrutura: 1 vCPU e 350 MB de RAM para o sistema inteiro, incluindo API, balanceamento, runtime, estruturas auxiliares e qualquer mecanismo de indexação.
Essa mudança parece pequena quando lida rapidamente no enunciado, mas na prática altera completamente a natureza da engenharia envolvida. O desafio passa a ser essencialmente computacional: como localizar rapidamente os vetores mais próximos sem comparar contra 3 milhões de elementos em cada requisição, e fazer isso sem ultrapassar limites extremamente apertados de CPU e memória?
Repositórios
- GitHub oficial da Rinha de Backend 2026
- GitHub da minha implementação na Rinha de Backend 2026 (.NET + Python + FAISS)
- Site oficial - Rinha de Backend com o Ranking
Em 2025, também participei da Rinha de Backend, com foco em arquitetura de sistemas distribuídos, concorrência e performance usando .NET, PostgreSQL, Grpc, Redis etc. Nesse contexto, desenvolvi a biblioteca ReactiveLock, voltada para controle de concorrência de forma reativa: Post: Desafio Rinha de Backend 2025: Análise técnica detalhada e o uso da biblioteca ReactiveLock
O objetivo da solução
Antes mesmo de pensar em implementação, eu tinha um pré-requisito bastante claro: precisava usar alguma alternativa pronta de mercado que coubesse nas constraints da Rinha.
Optei por não construir um motor vetorial do zero (apesar de esse caminho poder gerar as soluções mais rápidas), nem construir uma estrutura proprietária de indexação.
O meu objetivo foi encontrar uma tecnologia disponível no mercado que resolvesse busca vetorial de forma eficiente e que, ao mesmo tempo, conseguisse operar dentro do envelope extremamente apertado de CPU e memória imposto pela competição.
Foi exatamente esse filtro inicial que guiou toda a investigação. Antes de escrever qualquer linha da solução final, a pergunta passou a ser:
qual ferramenta pronta consegue consultar milhões de vetores sem estourar 350 MB/1vcpu e que, pelo menos passe no teste?
Essa pergunta é o verdadeiro coração da Rinha 2026 para muita gente, e foi exatamente ela que definiu a solução adotada por mim.
O que é busca vetorial de fato?
Em sistemas tradicionais, normalmente buscamos registros por correspondência exata. Quando uma aplicação consulta um banco relacional, por exemplo, ela costuma procurar um valor conhecido: um cliente por CPF, uma transação por ID, um pedido por número. O mecanismo de busca é baseado em igualdade. Existe uma chave, um índice e um valor exato que precisa ser encontrado.
Busca vetorial resolve um problema diferente. Em vez de procurar igualdade exata, ela procura proximidade matemática. Cada item passa a ser representado como um vetor numérico em um espaço multidimensional. Cada dimensão desse vetor representa uma característica observável do dado.
IA e uso de vetores
Em sistemas de IA modernos, dados como texto, eventos ou registros estruturados não são comparados diretamente. Eles são transformados em vetores (embeddings), que representam o comportamento ou significado desses dados em um espaço numérico.
A ideia central é a mesma usada na solução da Rinha 2026: em vez de procurar igualdade exata, o sistema trabalha com similaridade no espaço vetorial.
Isso permite tratar uma transação como um ponto em um espaço multidimensional e responder perguntas do tipo: quais registros históricos são mais parecidos com este novo evento.
Exemplos de uso
- Detecção de fraude em transações financeiras (contexto da Rinha de Backend 2026)
- Busca semântica em motores de busca (resultados por significado)
- Sistemas de recomendação (Netflix, Spotify, e-commerce)
- RAG em LLMs (recuperação de contexto relevante em bases de documentos)
- Busca por imagens similares
- Deduplicação de dados em grandes bases
No contexto da Rinha, uma transação de cartão pode ser convertida em um vetor contendo sinais como valor normalizado da compra, hora do dia, dia da semana, risco associado ao comerciante, risco geográfico, frequência recente do cartão, distância temporal em relação à última transação e outras features derivadas. Depois dessa transformação, a transação deixa de ser apenas um JSON com atributos independentes. Ela passa a ser um ponto em um espaço matemático.
Considere dois vetores simplificados:
Transação A → [0.42, 0.71, 0.08, 0.14]
Transação B → [0.44, 0.69, 0.10, 0.13]
Eles não são iguais. Nenhuma dimensão coincide exatamente. Ainda assim, estão muito próximos. E essa proximidade tem significado estatístico. A hipótese subjacente é simples: transações que ocupam regiões próximas no espaço vetorial tendem a compartilhar comportamento semelhante.
É exatamente essa ideia que torna a busca vetorial útil para detecção de fraude. Em vez de perguntar se já vimos exatamente aquela transação antes, o sistema pergunta algo muito mais útil:
já vimos transações parecidas com essa, e como elas se comportaram?
Por que o gargalo fica concentrado na busca vetorial
Em sistemas web tradicionais, é comum que o gargalo apareça em serialização JSON, middleware, pool de conexões, framework HTTP ou banco de dados.
Na Rinha 2026, o custo dominante ficou concentrado em um ponto muito específico:
encontrar rapidamente vizinhos próximos em um conjunto enorme de vetores
Como a consulta deve funcionar na Rinha 2026
Quando uma nova transação chega ao sistema, o primeiro passo é convertê-la para o mesmo espaço vetorial usado pelas referências históricas.
A pergunta que precisa ser respondida é:
quais transações históricas estão mais próximas desse novo vetor?
Matematicamente, isso normalmente é feito calculando uma medida de distância. A mais comum nesse tipo de cenário é a distância euclidiana.
Quanto menor esse valor, mais semelhantes são os vetores.
Na prática, o sistema busca os vizinhos mais próximos. Na solução adotada, o sistema recupera os 5 vizinhos mais próximos e observa quantos deles correspondem a fraudes históricas.
Se, por exemplo, 3 dos 5 vizinhos forem fraudes, o fraud_score será alto. Se apenas 1 ou nenhum vizinho for fraude, a transação tende a ser aprovada.
Conceitualmente, isso é muito próximo de um classificador k-nearest neighbors.
Onde a escala torna a pesquisa por força bruta inviável
Se existem 3 milhões de vetores, a solução mais direta seria calcular a distância entre o vetor novo e todos os vetores históricos, ordenar os resultados e selecionar os mais próximos.
Se cada vetor tiver 14 dimensões, uma única consulta envolve algo próximo de:
3.000.000 × 14 = 42.000.000 operações básicas
E isso vale apenas para uma requisição.
Com concorrência moderada, o custo cresce rapidamente.
Nesse ponto, o custo dominante passa a ser o cálculo de distância em larga escala.
A questão passa a ser:
como reduzir drasticamente o número de comparações necessárias por consulta?
O problema de memória é ainda pior
Mesmo antes da latência, existe um segundo obstáculo igualmente importante: memória.
Se os vetores forem armazenados em float32, cada dimensão consome 4 bytes. Com 14 dimensões, cada vetor ocupa:
14 × 4 = 56 bytes por vetor
Para 3 milhões de vetores:
56 × 3.000.000 = 168.000.000 bytes
≈ 160 MB
Esse número representa apenas o armazenamento bruto dos vetores.
Ainda faltam várias outras estruturas inevitáveis:
- labels ou classes associadas aos vetores
- índices auxiliares
- metadados
- overhead interno das estruturas de dados
- runtime da linguagem
- stack HTTP
- balanceador de carga
- buffers temporários
- alocações transitórias durante consultas
Mesmo armazenar os vetores já consome uma fração relevante do orçamento total de 350 MB.
Foi exatamente esse ponto que levou à decisão mais importante da solução:
usar compressão vetorial dentro do índice
FAISS - Facebook AI Similarity Search
É uma biblioteca criada pela equipe de pesquisa de inteligência artificial da Meta, originalmente Facebook, voltada para busca eficiente de similaridade em grandes coleções de vetores.
O FAISS foi escrito em C++, com foco em desempenho, e possui bindings oficiais para Python. Na solução da Rinha, o serviço de busca vetorial foi implementado em Python, usando esses bindings.
O papel do FAISS é reduzir o custo de busca de vizinhos mais próximos (nearest neighbors) em espaços vetoriais de alta dimensão, evitando a comparação exaustiva contra todos os elementos armazenados.
Em vez de uma abordagem ingênua de força bruta, ele suporta diferentes famílias de indexação e compressão de vetores, permitindo trade-offs explícitos entre precisão, memória e latência.
Entre os principais tipos de índices suportados estão:
- Brute-force search: comparação exata contra todos os vetores (baseline conceitual, caro em escala).
- Inverted-lists based indices (IVF): particionamento do espaço vetorial em listas associadas a centroides, reduzindo drasticamente o espaço de busca por consulta.
- Graph indices: como HNSW (Hierarchical Navigable Small World) e NSG (Navigating Spread-out Graph), que modelam o espaço vetorial como grafos para navegação eficiente em vizinhos aproximados.
- Locality-Sensitive Hashing (LSH): técnicas baseadas em hashing probabilístico para aproximar similaridade.
Além da indexação, o FAISS também implementa diferentes famílias de quantização vetorial, usadas para reduzir memória e acelerar consultas:
- Binary Quantization
- Scalar Quantization (SQ)
- Product Quantization (PQ), incluindo variantes como OPQ e PQFastScan
- Additive Quantization (AQ), incluindo RQ e LSQ
- Neural Quantization, como QINCO
O FAISS é fortemente otimizado para distância euclidiana (L2) e inner product, que são as métricas mais comuns em embeddings densos.
Otimização com AVX2
Em nível de CPU, o FAISS explora instruções SIMD (AVX2) para paralelizar operações de álgebra linear. Isso permite calcular distâncias e produtos internos processando múltiplas dimensões simultaneamente, reduzindo significativamente o custo por comparação em relação a implementações escalares tradicionais.
Esse detalhe é crítico para performance em cenários de alta carga, especialmente quando combinado com IVF e quantização.
Redução de comparações com IVF
O segundo ganho veio do IVF (Inverted File Index).
Em vez de manter todos os vetores em um único espaço plano, o índice divide o espaço vetorial em várias regiões chamadas listas invertidas.
Funciona assim:
- durante o treinamento, o FAISS executa um k-means sobre os vetores
- cada centroide passa a representar uma região do espaço
- cada vetor é associado ao centroide mais próximo
- na consulta, o sistema procura primeiro os centroides mais próximos
- a comparação detalhada acontece apenas dentro dessas regiões
Com isso, cada consulta trabalha apenas com uma pequena fração do conjunto total.
Foi isso que tornou a latência viável.
Testes realizados
Depois que o problema foi modelado corretamente, várias alternativas perderam atratividade.
PostgreSQL + pgvector (com HNSW / IVF) e MariaDB Vector (HNSW)
Funciona bem em muitos cenários reais.
Mas aqui havia problemas claros:
- overhead de banco relacional
- custo de memória elevado
- latência maior
- uso de disco
- pouca previsibilidade dentro de 350 MB
Bibliotecas de índice vetorial em .NET
Foram testadas também abordagens mais “leves” baseadas em bibliotecas locais:
HNSW.Net
Microsoft.SemanticKernel.Connectors.InMemory
Ambas implementações permitem indexação vetorial em memória com grafos aproximados (HNSW) ou estruturas in-memory otimizadas.
Mesmo com tuning de parâmetros (grau do grafo, efConstruction, M, efSearch), todas apresentaram o mesmo problema central: estouro de memória dentro do limite de 350 MB, principalmente com 3 milhões de vetores e overhead adicional do runtime e estruturas auxiliares.
Bancos vetoriais dedicados
Qdrant, Milvus e Redisearch entregam ótima performance.
Mas o custo de infraestrutura implícito nessas soluções era alto demais para o orçamento da competição.
O problema principal era estar dentro do limite de memória com respostas totais máximas até 2 segundos (restrição atual do teste).
A solução final: FAISS com IVF + quantização FP16
Depois de testar alternativas como PostgreSQL com pgvector, Qdrant e Redisearch, a solução que efetivamente fechou dentro do orçamento foi separar o sistema em dois blocos:
- APIs extremamente leves em .NET Native AOT
- Um serviço dedicado exclusivamente à busca vetorial em Python usando FAISS
O componente central foi um índice FAISS IVF com Scalar Quantization em FP16.
Essa escolha resolveu simultaneamente os dois problemas principais.
Redução de memória
Em vez de armazenar cada dimensão em float32, o índice armazena em float16.
Isso reduz o custo por dimensão de 4 bytes para 2 bytes.
Com 14 dimensões:
14 × 2 = 28 bytes por vetor
Para 3 milhões:
28 × 3.000.000 = 84 MB
Só essa decisão praticamente cortou o custo bruto dos vetores pela metade.
Por que os parâmetros escolhidos são críticos
A solução usou dois parâmetros fundamentais.
nlist = 4096
Esse valor define quantas regiões o espaço vetorial será dividido.
Com 3 milhões de vetores, isso significa algo próximo de:
3.000.000 / 4096 ≈ 732 vetores por lista, em média
O índice passa a trabalhar com milhares de pequenos grupos.
Esse número foi escolhido como compromisso entre:
- granularidade suficiente para reduzir comparações
- custo de memória ainda aceitável
- tempo de treinamento viável
nprobe = 16
Esse valor define quantas listas serão efetivamente visitadas em cada consulta.
Com 4096 listas totais, visitar apenas 16 significa explorar aproximadamente:
16 / 4096 ≈ 0,39%
Cada consulta examina apenas uma fração minúscula do índice.
A busca deixa de ser exata no sentido matemático absoluto, mas continua suficientemente boa para classificação de fraude.
Como a arquitetura foi organizada
Depois que ficou claro que o custo dominante estava na busca vetorial, a arquitetura foi organizada para isolar esse custo.
A solução final ficou dividida em quatro componentes.
1. Load balancer
Um HAProxy extremamente leve distribui as conexões.
Ele não interpreta payload e praticamente não consome CPU.
2. Duas APIs em .NET Native AOT
Cada instância da API faz apenas o mínimo necessário:
- recebe o JSON
- extrai os campos
- gera o vetor de 14 dimensões
- envia esse vetor ao serviço FAISS
- devolve a resposta final
O uso de Native AOT foi importante porque reduziu:
- tempo de startup
- footprint de memória
- overhead do runtime
3. Serviço dedicado de busca vetorial em Python
Esse processo roda isolado, implementado em Python e usa os bindings do FAISS para carregar o índice em memória e responder apenas consultas vetoriais.
Ele recebe algo como:
{ "vector": [ ... ] }
Executa a busca dos 5 vizinhos mais próximos e devolve apenas o essencial:
{ "fraud_count": 3 }
Isso mantém o tráfego interno mínimo e evita serialização desnecessária.
Detalhe importante: o índice é pré-construído
Treinar o índice em tempo de inicialização seria inviável.
O treinamento envolve:
- ler os 3 milhões de vetores
- executar k-means
- construir as listas invertidas
- quantizar os vetores
- persistir o índice
Esse custo é alto, mas acontece uma única vez.
A solução adotada foi simples:
o índice é construído previamente e salvo em disco, no build da imagem docker
Na inicialização normal do sistema, o serviço FAISS apenas:
- carrega o índice pronto
- carrega os labels
- ajusta
nprobe - começa a responder consultas
Isso reduz drasticamente o tempo de inicialização e evita custo computacional no caminho crítico.
Resultado local (K6)
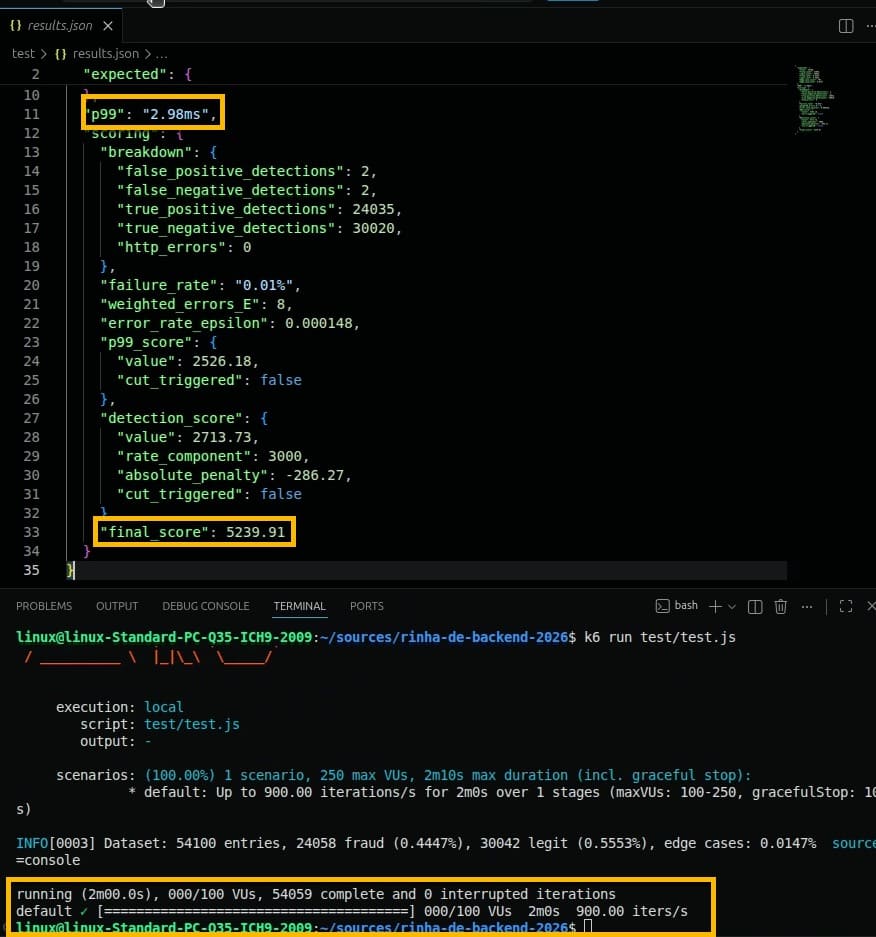
No teste local com K6, a carga total foi de 54.100 requisições, com distribuição esperada entre classes (44,47% fraudes e 55,53% legítimas).
O ambiente de execução foi um Ryzen 5 5500 rodando em virtualização sobre Proxmox, o que adiciona uma camada de abstração de hardware ao cenário de teste.
A latência ficou extremamente baixa, com p99 de 2,98 ms e zero erros HTTP.
Na camada de detecção, o sistema registrou apenas 4 erros no total (2 falsos positivos e 2 falsos negativos), resultando em taxa de erro de 0,01%.
O score final foi de 5239,91, impactado apenas por penalizações residuais do modelo, sem limitação relevante de performance ou estabilidade.
Resultado oficial no GitHub
A submissão foi enviada via PR 2056 e uma issue foi aberta no repositório oficial da Rinha de Backend 2026: Issue 2085.
O ambiente de benchmark executa automaticamente os testes após o registro da issue, sem intervenção manual em um Mac Mini do Francisco Zanfranceschi, como ele cita aqui, o que representa uma evolução considerável em relação às edições anteriores.
Após executado no ambiente oficial, o resultado registrado foi um p99 de 1195.07ms, diferença atribuída à vCPU do ambiente de benchmark, distinta da utilizada nos testes locais.
Posteriormente, foi necessário ajustar o NPROBE de 16 para 8 e realizar pequenas alterações no docker-compose. Com isso, foi possível atingir 114.50ms no teste oficial registrado em Issue 2376. A alteração do nprobe elevou as falhas de detecção de 4 para 8.
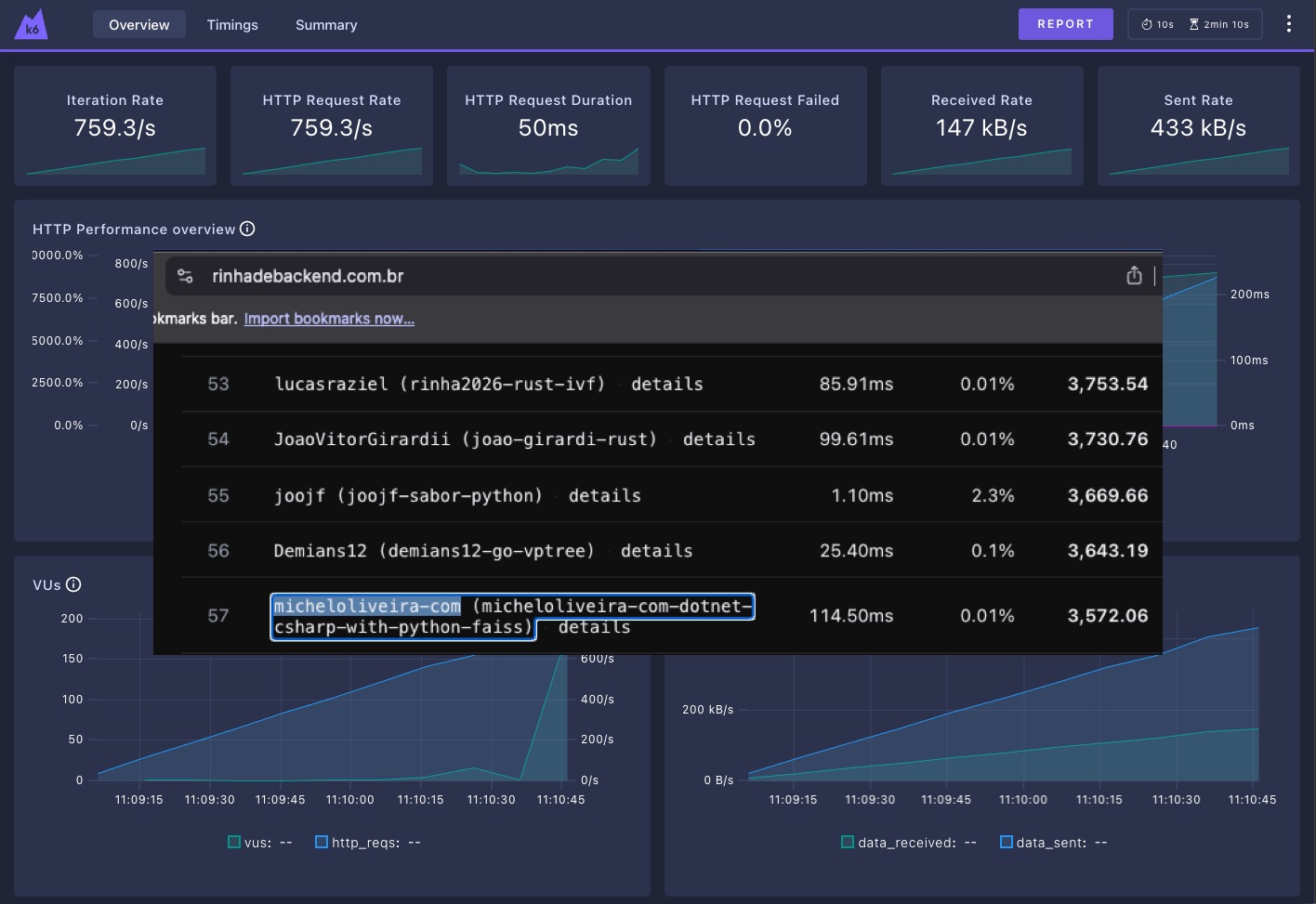
Também será possível acompanhar o ranking aqui:
Tratando-se apenas de uma prévia oficial. O resultado consolidado e a data do teste final ainda estão por definir.
Conclusão
O gargalo da Rinha 2026 não está na linguagem utilizada, mas na escolha e configuração (ou construção) do motor de busca vetorial. A separação entre uma API leve em .NET AOT e um serviço dedicado de busca em FAISS mostrou-se mais relevante do que qualquer otimização incremental apenas na camada HTTP.
Ao deslocar o custo computacional para um índice ANN (IVF com quantização FP16), o sistema passa a operar dentro do limite restrito de 1 vCPU e 350 MB sem depender de varredura exaustiva ou estruturas tradicionais de persistência. Nesse modelo, a API atua apenas como camada de orquestração, enquanto a responsabilidade crítica de similaridade fica concentrada no índice.
O trade-off: redução de precisão absoluta em troca de viabilidade operacional e latência previsível. Em alto volume, esse compromisso se mostra aceitável porque o problema não exige resposta exata, mas recuperação aproximada consistente.
Referências
- Todos os Posts - Rinha De Backend
- Site oficial - Rinha de Backend com o Ranking
- Desafio Rinha de Backend 2025: Análise técnica detalhada e o uso da biblioteca ReactiveLock
- ReactiveLock – Um case pronto para produção da Rinha de Backend 2025
- O Teorema CAP na Prática: Lições da Rinha de Backend 2025
- Desafio de Performance - Rinha de Backend 2025 - Insights em C# + PostgreSQL + Redis
- FAISS (Facebook AI Similarity Search) – Wikipedia
- Inverted index – Wikipedia
- GitHub - FAISS
Conecte-se para transformar sua tecnologia!
Saiba mais e entre em contato: