Desafio Rinha de Backend 2025: Análise técnica detalhada e o uso da biblioteca de lock ReactiveLock

Mostrar/Ocultar
Introdução
O desafio da Rinha de Backend 2025 foi um exercício de engenharia em condições de alta concorrência, limitação de recursos (350MB de memória, 1.5 CPUs totais), e instabilidade nos serviços.
Esta terceira edição do desafio consolidou-se como a mais interessante e desafiadora até então na minha opinião, tanto pela complexidade dos requisitos quanto pelo ambiente restritivo imposto aos participantes.
Podemos considerar, de forma ilustrativa, que a rinha de backend tinha um teste que representava centenas de pessoas realizando transferências financeiras. Nesse contexto, o próprio framework de testes da Rinha de Backend funcionava como um “Banco Central”, responsável por auditar e validar a integridade das operações realizadas, garantindo que os resultados refletissem corretamente a consistência e o desempenho de cada solução, no qual também disponibilizava as APIs para as transferências.
O desafio
O objetivo principal era processar pagamentos em duas APIs distintas - a principal (default) e a secundária (fallback) - com diferentes taxas e garantias de consistência. A taxa maior era aplicada ao fallback, enquanto a taxa menor correspondia à API default. Divergências nos pagamentos geravam multa de 35% sobre o saldo final, enquanto a latência impactava bônus de performance.
A partir dos pagamentos processados durante os testes, era calculado um score que representava o valor total de pagamentos realizados com sucesso, já com a dedução das taxas, penalidades e bônus por baixa latência. Esse score servia de base para a formação de um ranking entre os participantes, incentivando estratégias que maximizassem a eficiência e a consistência das soluções.
No teste final, 603 usuários virtuais acessavam os endpoints, simulando um cenário distribuído com load balancer e múltiplas instâncias de API em containers.
As soluções implementadas pelos participantes na maioria dos casos tinham caráter estritamente experimental e foram concebidas para o contexto específico do desafio. Elas não necessariamente correspondiam às melhores práticas para ambientes de produção - por exemplo, o uso de Redis/memória para armazenamento de dados críticos ou a persistência tardia, que poderiam introduzir riscos de consistência e durabilidade que exigiriam mecanismos mais robustos em sistemas reais como replicação, transações distribuídas ou persistência durável.
Apesar disso, excelentes soluções surgiram ao longo do desafio e no meu caso, criei uma biblioteca de lock distribuído projetada desde o início para uso em produção, com foco em confiabilidade, desempenho e facilidade de integração como pode ser conferido em Blog: ReactiveLock – Um case pronto para produção da Rinha de Backend 2025.
Arquitetura mínima da API
A API mínima exigida era:
- GET /payments-summary: endpoint de sumário - retorna total de pagamentos por endpoint (default/fallback) e, se informado, por intervalo de datas.
- POST /payments: endpoint de pagamentos - processa / enfileira um pagamento.
- POST /purge-payments (opcional): endpoint de limpeza - limpa a base de pagamentos.
O desafio principal era garantir consistência absoluta, mesmo sob falhas temporárias e alta concorrência - algo que, na prática, assegurava maiores pontuações na maior parte dos casos, já que inconsistências impactavam diretamente no score e na posição no ranking devido à multa de 35% aplicada.
A solução deveria ser orquestrada via Docker Compose, com no mínimo duas instâncias da API e limite total de 1.5 vCPU e 350MB de RAM, com um load balancer configurado em round-robin que distribui as requisições de pagamentos e consultas de sumário entre as instâncias, exigindo que os participantes lidassem com tradeoffs de sistemas distribuídos.
Solução com Redis
Uma das minhas soluções utilizou Redis como backbone para pub/sub e armazenamento:
- Enfileiramento de pagamentos com processamento em 10 workers contínuos por instância.
- Armazenamento de pagamentos em lotes de 100 antes da persistência.
- Sumário consultado diretamente do Redis consolidado.
Infraestrutura:
API:
Mesmo com alto throughput, havia risco de inconsistência entre pagamentos pendentes na memória e sumários consultados, devido à concorrência entre gravações e leituras.
A versão incluindo PostgreSQL e otimizações em C# foi abordada neste post:
Blog: Meus Insights sobre o Desafio da Rinha de Backend 2025
Problemas enfrentados
Durante os testes, foram observados desafios críticos:
- Pagamentos pendentes: requisições em andamento poderiam não estar refletidas no sumário.
- Instabilidade dos serviços da rinha: delays de até 5 segundos para processar cada pagamento, com possibilidade de falha.
- Sumários frequentes: a Rinha consultava os valores a cada 10 segundos, exigindo dados precisos.
- Concorrência distribuída: múltiplas instâncias da API precisavam sincronizar acesso a recursos compartilhados.
Esses fatores exigiam uma sintonia fina entre workers, persistência e leitura de sumários.
Estratégias adotadas pelos participantes
Durante o desafio, os participantes exploraram algumas abordagens para lidar com a concorrência e a instabilidade dos serviços de pagamento:
- Escolher o melhor meio de pagamento com menor latência: reduzindo o risco de inconsistência nas verificações do teste.
- Persistir pagamentos o mais rápido possível: garantindo que os registros estivessem disponíveis imediatamente para consulta.
- Sincronização de processos via lock distribuído: esta abordagem foi a que utilizei, criando a biblioteca ReactiveLock para gerenciar locks distribuídos de forma eficiente entre instâncias e processos concorrentes.
Introdução ao ReactiveLock
Para resolver os problemas de concorrência, utilizei a biblioteca ReactiveLock para gerenciar locks distribuídos.
Foram criados três tipos de locks:
- Lock de requisições ativas: particionado por data, garantindo que sumários não fossem calculados enquanto pagamentos pendentes existissem.
- Lock de registros pendentes: assegurava que todos os pagamentos em memória fossem persistidos antes da leitura.
- Lock de sumário ativo: bloqueava leituras concorrentes conflitantes com gravações.
Código de inicialização dos locks:
- Program.cs:
builder.Services.InitializeDistributedRedisReactiveLock(Dns.GetHostName());
var opts = builder.Configuration
.Get<DefaultOptions>()!;
builder.Services.AddDistributedRedisReactiveLock(Constant.DEFAULT_PROCESSOR_ERROR_THRESHOLD_NAME,
busyThreshold: opts.DEFAULT_PROCESSOR_CIRCUIT_ERROR_THRESHOLD_SECONDS);
builder.Services.AddDistributedRedisReactiveLock(Constant.REACTIVELOCK_HTTP_NAME);
builder.Services.AddDistributedRedisReactiveLock(Constant.REACTIVELOCK_REDIS_NAME);
builder.Services.AddDistributedRedisReactiveLock(Constant.REACTIVELOCK_API_PAYMENTS_SUMMARY_NAME, [
async(sp) => {
var summary = sp.GetRequiredService<PaymentSummaryService>();
await summary.FlushWhileGateBlockedAsync();
}
]);
var app = builder.Build();
await app.UseDistributedRedisReactiveLockAsync();
Código de controle dos locks por requisição particionado:
- CountingHandler.cs:
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
var shouldIncrement = true;
if (request.Options.TryGetValue(new HttpRequestOptionsKey<DateTimeOffset>("RequestedAt"), out var requestedAt))
{
var currentRunningRanges = RunningPaymentsSummaryData.CurrentRanges.ToList();
if (currentRunningRanges.Any())
{
bool requestIsNotInsideAnySummaryRange = !currentRunningRanges.Any(range =>
(!range.from.HasValue || requestedAt >= range.from.Value) &&
(!range.to.HasValue || requestedAt <= range.to.Value)
);
if (requestIsNotInsideAnySummaryRange)
{
shouldIncrement = false;
}
}
}
if (shouldIncrement)
await ReactiveLockTrackerController.IncrementAsync().ConfigureAwait(false);
try
{
return await base.SendAsync(request, cancellationToken).ConfigureAwait(false);
}
finally
{
if (shouldIncrement)
await ReactiveLockTrackerController.DecrementAsync().ConfigureAwait(false);
}
}
A infraestrutura após o ReactiveLock:
Para mais detalhes, consulte o código completo no GitHub:
Estratégia de espera e partição de locks
Para cada requisição de sumário:
- Locks eram particionados por intervalo de datas, afetando apenas pagamentos relevantes.
- Processos pendentes fora do intervalo de datas eram pausados temporariamente.
- Máximo de 1,3 segundos de espera para o processamento total das requisições e lotes pendentes dentro do intervalo de datas.
Essa abordagem mitigava os efeitos do Teorema CAP, priorizando consistência sem comprometer totalmente a disponibilidade.
Mais detalhes em: Blog: O Teorema Cap na Rinha de Backend 2025
Código que garante a espera pelos locks no endpoint de sumário:
- PaymentSummaryService.cs:
await WaitWithTimeoutAsync(async () =>
{
await redisChannelBlockingGate.WaitIfBlockedAsync().ConfigureAwait(false);
await channelBlockingGate.WaitIfBlockedAsync().ConfigureAwait(false);
}, timeout: TimeSpan.FromSeconds(1.3)).ConfigureAwait(false);
Código que garante a espera das requisições enquanto um endpoint de sumário estivesse sendo processado:
- PaymentService.cs:
await ReactiveLockTrackerState.WaitIfBlockedAsync().ConfigureAwait(false);
(HttpResponseMessage response, string processor, DateTimeOffset requestedAt)
= await PaymentProcessorService.ProcessPaymentAsync(request);
Para mais detalhes, consulte o código completo no GitHub:
Fluxo detalhado de processamento
- Recepção do pagamento: o POST /payments publica no Redis Pub/Sub.
- Worker enfileira: cada worker consome os pagamentos pendentes e mantém lotes em memória após as requisições da API da Rinha.
- Persistência controlada: antes do sumário, todos os lotes pendentes são gravados continuamente.
- Leitura do sumário: locks garantem que apenas dados consistentes sejam retornados.
Código que gerenciava os lotes em memória, com notificação dos locks:
- PaymentBatchInserterService.cs:
public async Task<int> AddAsync(PaymentInsertParameters payment)
{
await ReactiveLockTrackerController.IncrementAsync().ConfigureAwait(false);
Buffer.Enqueue(payment);
if (Buffer.Count >= Options.BATCH_SIZE)
{
return await FlushBatchAsync().ConfigureAwait(false);
}
return 0;
}
public async Task<int> FlushBatchAsync()
{
if (Buffer.IsEmpty)
return 0;
int totalInserted = 0;
while (!Buffer.IsEmpty)
{
var batch = new List<PaymentInsertParameters>(Options.BATCH_SIZE);
while (batch.Count < Options.BATCH_SIZE && Buffer.TryDequeue(out var item))
batch.Add(item);
if (batch.Count == 0)
break;
foreach (var payment in batch)
{
string json = JsonSerializer.Serialize(payment, JsonContext.Default.PaymentInsertParameters);
await RedisDb.ListRightPushAsync(Constant.REDIS_PAYMENTS_BATCH_KEY, json);
}
totalInserted += batch.Count;
await ReactiveLockTrackerController.DecrementAsync(batch.Count).ConfigureAwait(false);
}
return totalInserted;
}
- Program.cs:
builder.Services.AddDistributedRedisReactiveLock(Constant.REACTIVELOCK_API_PAYMENTS_SUMMARY_NAME, [
async(sp) => {
var summary = sp.GetRequiredService<PaymentSummaryService>();
await summary.FlushWhileGateBlockedAsync();
}
]);
Para mais detalhes, consulte o código completo no GitHub:
Estratégia de fallback em instabilidade
Durante o teste da Rinha de Backend, os serviços secundários apresentavam indisponibilidade intermitente, e o PaymentProcessorService precisava lidar com isso de forma consistente e eficiente.
Um lock específico para a estratégia de fallback foi criado para coordenar essas tentativas. A estratégia adotada foi:
- Circuit break: se o endpoint principal apresentasse falhas contínuas por 20 segundos, o sistema acionava o fallback automaticamente.
- Verificação de bloqueio via ReactiveLock: antes de enviar qualquer pagamento, o serviço checa se há um lock para agir em circuit break.
- Fallback intermitente: quando o serviço principal estava instável, os pagamentos eram enviados para o processador secundário (fallback).
- Tentativa especial a cada 2 envios: mesmo em estado de fallback, a cada duas tentativas, o serviço tentava enviar para o processador principal, garantindo que nenhum pagamento ficasse permanentemente desviado.
- Lock de fallback específico: gerenciava apenas a lógica de envio durante instabilidade.
- Lock atualizado conforme resultado: Em caso de sucesso no principal, o lock era decrementado. Em caso de falha ou fallback, o lock era incrementado.
- Prioridade por endpoint: sempre que possível, os pagamentos eram direcionados para a API principal para reduzir inconsistências.
- Retries controlados: os workers repetiam a tentativa de persistência dos pagamentos até que fossem processados com sucesso.
Essa abordagem garante que, mesmo diante de instabilidade intermitente, os sumários retornam consistentes, mantendo a integridade dos dados e a confiabilidade do sistema.
Declaração do Threshold de 20 segundos para o lock do circuit break:
- Program.cs:
builder.Services.AddDistributedRedisReactiveLock(Constant.DEFAULT_PROCESSOR_ERROR_THRESHOLD_NAME,
busyThreshold: opts.DEFAULT_PROCESSOR_CIRCUIT_ERROR_THRESHOLD_SECONDS);
- PaymentProcessorService.cs:
public async Task<(HttpResponseMessage response, string processor, DateTimeOffset requestedAt)> ProcessPaymentAsync(PaymentRequest request)
{
var requestedAt = DateTimeOffset.UtcNow;
string processor = Constant.DEFAULT_PROCESSOR_NAME;
string jsonString = $@"{{
""amount"": {request.Amount},
""requestedAt"": ""{requestedAt:o}"",
""correlationId"": ""{request.CorrelationId}""
}}";
var content = new StringContent(jsonString, Encoding.UTF8, "application/json");
var httpRequest = new HttpRequestMessage(HttpMethod.Post, "/payments")
{
Content = content
};
httpRequest.Options.Set(new HttpRequestOptionsKey<DateTimeOffset>("RequestedAt"), requestedAt);
HttpClient requestClient = HttpDefault;
if (await ReactiveLockTrackerState.IsBlockedAsync())
{
if (ReactiveLockTrackerController.GetActualCount() % 2 == 0)
{
requestClient = HttpFallback;
}
}
var message = await requestClient.SendAsync(httpRequest).ConfigureAwait(false);
if (requestClient == HttpDefault)
{
var actualCount = ReactiveLockTrackerController.GetActualCount();
if (message.IsSuccessStatusCode && actualCount > 0)
{
ConsoleWriterService.WriteLine($"Lock decremented.");
await ReactiveLockTrackerController.DecrementAsync().ConfigureAwait(false);
}
else if (!message.IsSuccessStatusCode)
{
await IncrementLockIfPossible(actualCount).ConfigureAwait(false);
}
}
if (requestClient == HttpFallback)
{
var actualCount = ReactiveLockTrackerController.GetActualCount();
await IncrementLockIfPossible(actualCount).ConfigureAwait(false);
processor = Constant.FALLBACK_PROCESSOR_NAME;
ConsoleWriterService.WriteLine($"Fallback is called.");
}
return (message, processor, requestedAt);
}
Para mais detalhes, consulte o código completo no GitHub:
Benefícios observados
- Consistência garantida: leituras do sumário refletiam a realidade.
- Baixo impacto de latência: locks particionados minimizaram bloqueios.
- Escalabilidade: distribuição de locks entre instâncias evitou gargalos.
- Resiliência: instabilidade de APIs secundárias não causava divergência no sumário.
- Simplicidade na implementação: ReactiveLock abstrai toda a complexidade de sincronização distribuída.
Riscos potenciais
- Lock dessincronizado: o ReactiveLock, apesar de replicar próximo de tempo real, não é em tempo real e algum atraso na propagação do lock poderia deixá-lo fora de sincronia, gerando inconsistências temporárias. O uso recomendado da biblioteca é sempre em conjunto com outra camada de lock (geralmente de maior custo, justamente para aumentar a performance) como abordo no case em: Blog: ReactiveLock – Um case pronto para produção da Rinha de Backend 2025.
- Persistência lenta: se a gravação dos pagamentos for mais demorada que o esperado, o sumário poderia não refletir o estado real, como aconteceu potencialmente com algumas versões em PostgreSQL e gRPC que enviei.
- Falha parcial de instâncias: se algumas instâncias da API ou workers ficarem indisponíveis por um período, mesmo com locks distribuídos, podem ocorrer situações em que parte dos pagamentos não é processada ou o sumário fica incompleto, exigindo mecanismos de reprocessamento ou conciliação. A biblioteca atualmente suporta recuperação gerenciada em falhas de qualquer tipo.
Minhas posições
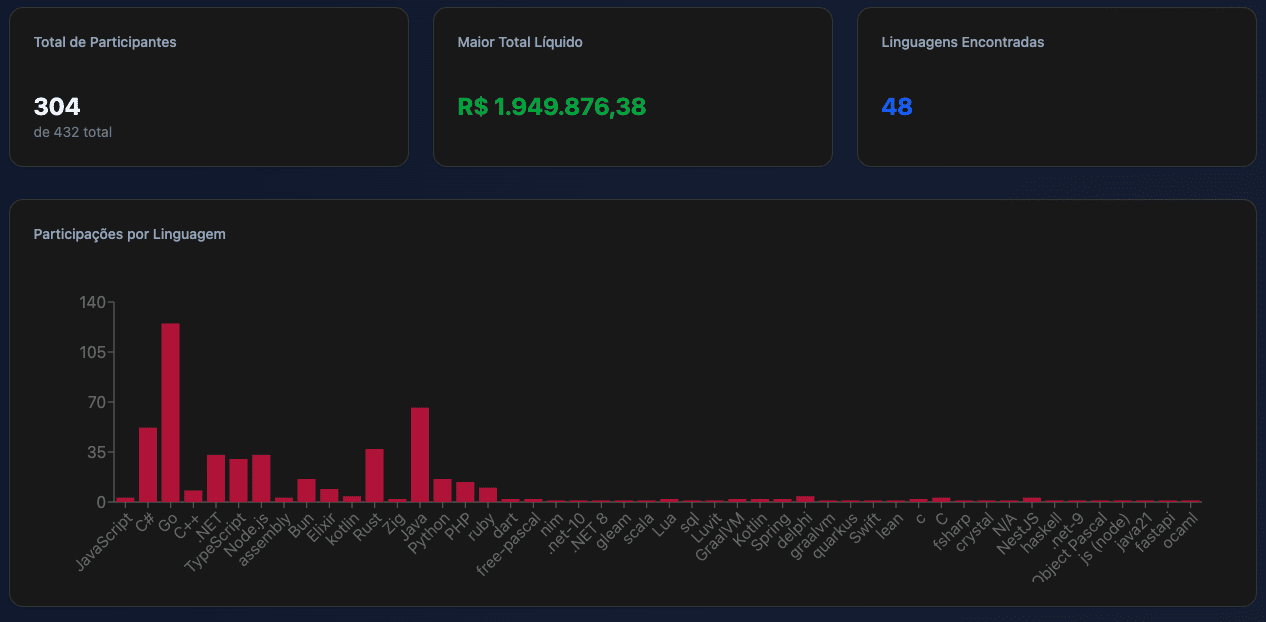
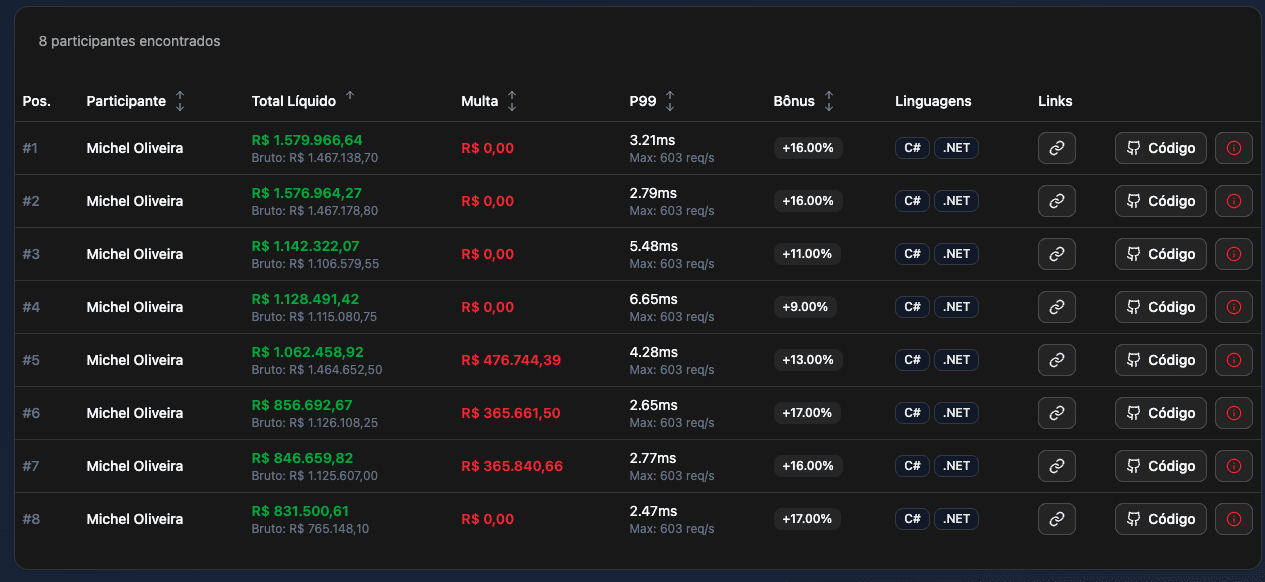
No teste final, concluí em 6º lugar na categoria Microsoft e 34º no geral com 1.579.966,64 pontos, considerando apenas participantes únicos, que foram mais de 300 em aproximadamente 48 linguagens de programação. Na prévia, fiquei em 1º lugar na categoria Microsoft e 17º no ranking geral. Foi possível alcançar 2~3ms de P99 entre os rankings.
Ao longo do desafio, enviei 8 versões diferentes utilizando combinações de C# em .NET 10 com Redis, gRPC e Postgres com Nginx / HAProxy em 48 pull requests ao repositório oficial, buscando otimizar tanto desempenho de I/O quanto a escolha dos meios de pagamento, onde priorizei o meio de pagamento principal mesmo diante de incertezas no teste final, mas ainda utilizando o meio secundário, embora de forma otimista.
Ranking Parcial:
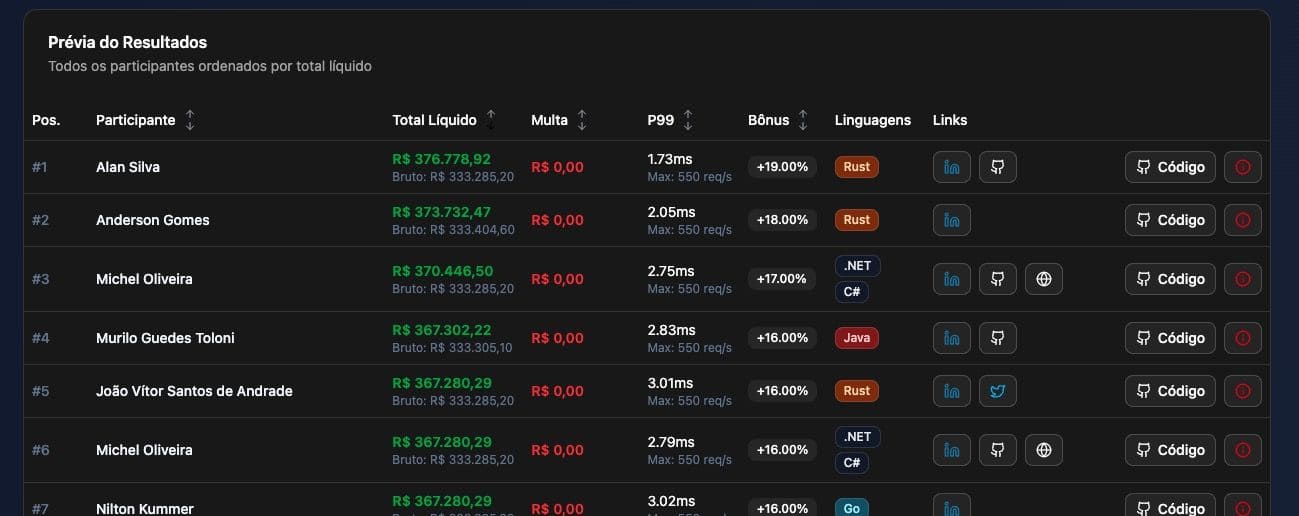 Ranking Final Agrupado:
Ranking Final Agrupado:
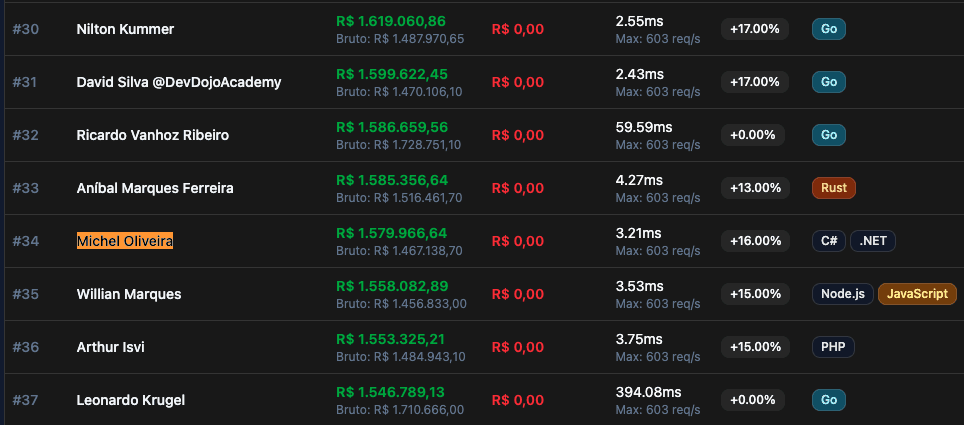 Ranking Final - Todas as soluções:
Ranking Final - Todas as soluções:
Considerações finais
O Desafio Rinha de Backend 2025 mostrou que:
- Alta concorrência, performance e consistência podem coexistir quando há uso de locks distribuídos.
- Mesmo o teste da Rinha de Backend não representando um cenário totalmente real que ocorreria em produção, foi um excelente laboratório para testar arquiteturas distribuídas sob alta carga e validar estratégias de consistência e resiliência.
- O ReactiveLock foi eficiente em sincronizar os processos assíncronos e distribuídos.
- A combinação Redis + ReactiveLock ofereceu uma solução simples, performática e resiliente, gerando um case pronto para produção.
Referências
- Blog: ReactiveLock – Um case pronto para produção da Rinha de Backend 2025
- Blog: Meus Insights sobre o Desafio da Rinha de Backend 2025
- Blog: O Teorema Cap na Rinha de Backend 2025
- Biblioteca ReactiveLock Core no NuGet
- Ecossistema ReactiveLock no NuGet
- Rinha de Backend 2025 - Github do Desafio
- Rinha de Backend 2025 - Github da Minha Versão com gRPC
- Rinha de Backend 2025 - Github da Minha Versão com Redis + gRPC
- Rinha de Backend 2025 – Github da Minha Versão com Postgres
- Rinha de Backend 2025 – Github da Minha Versão com Redis
Conecte-se para transformar sua tecnologia!
Saiba mais e entre em contato: