Reduzindo mais de 90% da latência na Rinha de Backend 2026 executando FAISS diretamente dentro das APIs .NET
Mostrar/Ocultar
Introdução
Na primeira versão da minha solução para a Rinha de Backend 2026, a busca vetorial rodava em um serviço separado em Python utilizando FAISS (Facebook AI Similarity Search), enquanto as APIs HTTP eram implementadas em .NET Native AOT.
A arquitetura funcionava bem e conseguia operar dentro das constraints da competição a ~100ms de latência p99 em:
- 1 vCPU.
- 350 MB de RAM.
- 3 milhões de vetores.
O índice IVF (Inverted File Index) com quantização FP16 (Floating Point 16-bit) já resolve o principal problema matemático da Rinha: Tornar viável a busca aproximada em milhões de vetores sem brute force.
Só que, depois disso, o gargalo deixou de estar na busca vetorial. O custo dominante passou a ser a movimentação de dados entre processos e stacks.
Repositórios
- GitHub oficial da Rinha de Backend 2026
- GitHub da minha implementação na Rinha de Backend 2026 (.NET + FAISS)
- Desafio de Performance - Rinha de Backend 2026 - Insights da Minha Versão em C# AOT + Similarity Search em Python com FAISS
- GitHub da minha implementação na Rinha de Backend 2026 (.NET + Python + FAISS)
- Site oficial - Rinha de Backend com o Ranking
Por que o Python virou gargalo
A escolha do Python aconteceu principalmente por um motivo bastante simples: O FAISS possui bindings oficiais e maduros para Python, enquanto o ecossistema .NET não possui.
Atualmente, a alternativa mais estável e documentada continua sendo utilizar diretamente os bindings oficiais mantidos pela Meta / Facebook (ou chamar diretamente em C++).
A segunda versão da solução passa a utilizar a biblioteca Binozo/Faiss.NET, ainda em versão preview, permitindo integrar o FAISS diretamente dentro do processo das APIs .NET através de interop com a biblioteca nativa em C++.
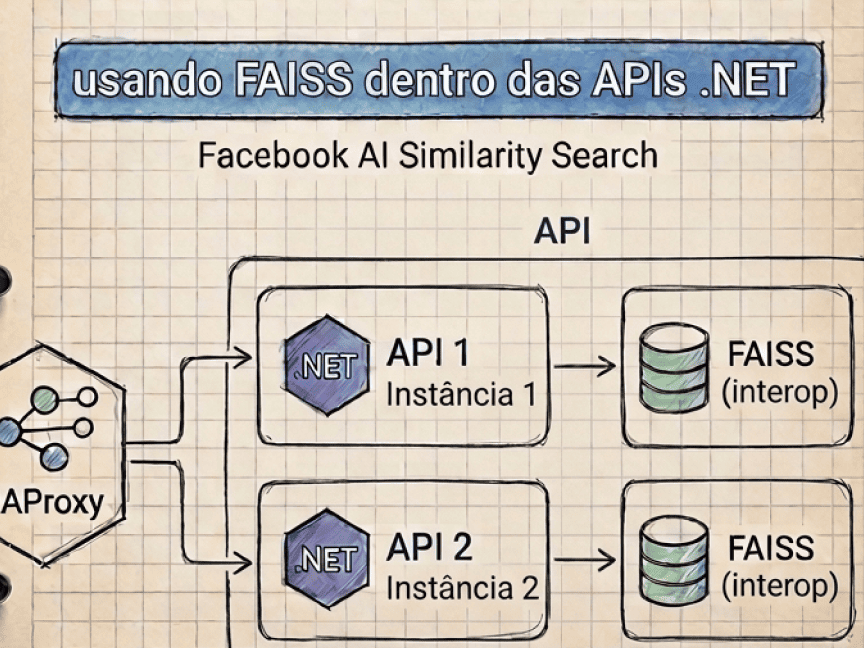
A primeira arquitetura
A arquitetura inicial ficou organizada desta forma:
Cada requisição seguia basicamente este fluxo:
- A API recebia o JSON.
- Gerava o vetor.
- Serializava os dados.
- Enviava via HTTP para o processo Python.
- O Python executava a busca FAISS.
- A resposta era serializada novamente.
- O resultado voltava para a API.
O problema é que o overhead arquitetural pesa muito.
Mesmo rodando local, ainda existem:
- Serialização e desserialização.
- Cópia de buffers.
- Syscall de socket.
- Context switching.
- Runtime Python.
- Servidor HTTP interno.
O FAISS já executava rápido. O problema estava em tudo que acontecia ao redor dele.
O que levou à mudança
Em determinado momento ficou claro que o serviço Python praticamente não possuía lógica própria.
Ele funcionava basicamente como uma ponte entre a API .NET e a biblioteca nativa do FAISS, sendo que os bindings Python apenas encapsulam chamadas para o código C++.
O fluxo ficava algo próximo disso:
A partir disso, a pergunta passou a ser inevitável:
por que não chamar a biblioteca C++ diretamente?
A nova arquitetura
A segunda versão remove completamente o processo Python. O FAISS passa a ser carregado diretamente dentro das APIs .NET via interop.
A diferença é enorme. A latência cai de:
112.40ms
para:
10.47ms
Mais de 90% de redução sem mudanças relevantes no algoritmo vetorial.
O IVF continua o mesmo. O FP16 continua o mesmo. A principal mudança acontece na arquitetura.
O que deixa de existir
Quando o índice roda dentro do mesmo processo da API, o caminho crítico da requisição fica muito menor.
Antes:
Depois:
Isso elimina:
- HTTP interno.
- Serialização JSON intermediária.
- Desserialização.
- Buffers TCP.
- Cópia excessiva de memória.
- Troca de contexto entre processos.
- Runtime Python.
- Serviço auxiliar.
O vetor sai praticamente direto do parser HTTP para a biblioteca nativa.
Trade-offs
A nova arquitetura fica muito mais eficiente, mas também mais instável.
Os bindings Python escondem praticamente toda a complexidade do FAISS.
Quando o acesso passa a ocorrer diretamente via interop, começam a aparecer problemas como:
- ABI (Application binary interface) compatibility.
- Gerenciamento manual de memória.
- Alinhamento de estruturas.
- Lifecycle manual do índice.
- Debugging nativo.
- Ponteiros inválidos.
- Crashes fora do runtime gerenciado.
Parte da simplicidade operacional é trocada por eficiência.
Resultados oficiais
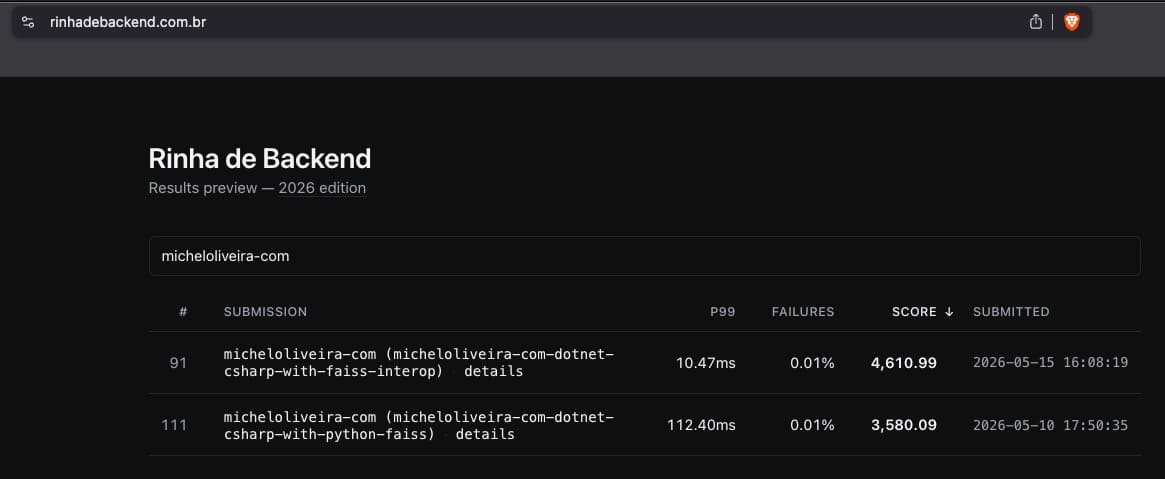
A versão final evidencia o impacto da integração direta do FAISS nas APIs .NET Native AOT.
- p99: 10.47ms.
- Pontos: 4.610,99.
Em relação à arquitetura anterior (~112ms), a redução representa mais de 90% da latência e o incremento de 1.030,9 pontos.
Resultados locais
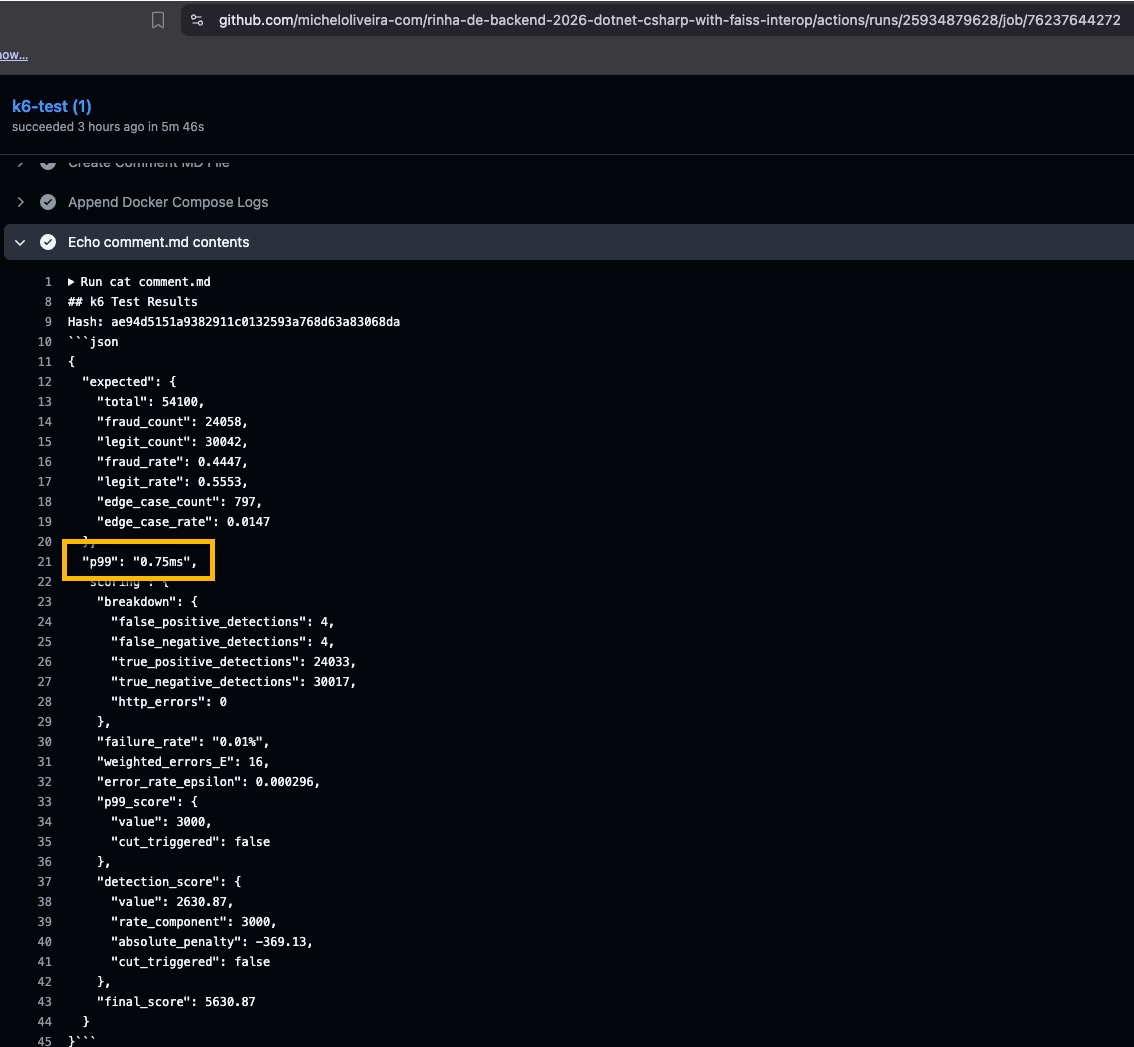
No teste local, observa-se p99 de 0.75ms. A diferença decorre do ambiente de execução, já que o hardware utilizado no benchmark local é um Mac Mini, conforme descrito no repositório da Rinha.
Execução do benchmark no GitHub Actions: GitHub Actions Run (Rinha de Backend 2026 - FAISS .NET AOT)
Próximos passos
Os próximos ajustes focam em duas frentes principais: Redução adicional de latência e melhoria de acurácia, mitigando os falso-positivos que impactam diretamente a pontuação no benchmark.
Nos próximos dias, estarei fazendo otimizações no pipeline de busca e no uso do índice vetorial, além de ajustes finos nos parâmetros para equilibrar desempenho e precisão.
A evolução dessa versão será compartilhada conforme os experimentos forem sendo validados.
Conclusão
A primeira versão resolve corretamente o problema matemático da Rinha 2026 usando IVF e quantização FP16. A segunda resolve o problema arquitetural.
Ao remover completamente o processo Python e integrar o FAISS diretamente dentro das APIs .NET Native AOT, praticamente todo o overhead intermediário desaparece.
O resultado é uma redução de latência de 112.40ms para 10.47ms sem mudanças substanciais no algoritmo de busca vetorial.
Depois que a busca fica suficientemente eficiente, o maior custo do sistema deixa de ser computação e passa a ser movimentação de dados entre camadas desnecessárias.
Referências
- Todos os Posts - Rinha De Backend
- Site oficial - Rinha de Backend com o Ranking
- Desafio de Performance - Rinha de Backend 2026 - Insights da Minha Versão em C# AOT + Similarity Search em Python com FAISS
- Desafio Rinha de Backend 2025: Análise técnica detalhada e o uso da biblioteca ReactiveLock
- ReactiveLock – Um case pronto para produção da Rinha de Backend 2025
- Binozo/Faiss.NET
- O Teorema CAP na Prática: Lições da Rinha de Backend 2025
- Desafio de Performance - Rinha de Backend 2025 - Insights em C# + PostgreSQL + Redis
- FAISS (Facebook AI Similarity Search) – Wikipedia
- Inverted index – Wikipedia
- GitHub - FAISS
Conecte-se para transformar sua tecnologia!
Saiba mais e entre em contato: