O Teorema CAP na Prática: Lições da Rinha de Backend 2025
Mostrar/Ocultar
Durante a Rinha de Backend 2025, os participantes enfrentaram um desafio que ia além da performance bruta. O objetivo era construir sistemas distribuídos rápidos, confiáveis e resilientes diante de falhas. A proposta parecia simples: processar pagamentos entre dois serviços que poderiam ficar instáveis. No entanto, à medida que o sistema era colocado sob carga, surgia uma questão importante: o que acontece quando partes do sistema deixam de se comunicar e / ou estão fora de sincronia?
Esse tipo de situação leva inevitavelmente à discussão sobre o Teorema CAP. Ele é um conceito central em sistemas distribuídos, mas muitas vezes é interpretado de forma equivocada. Neste artigo, vamos esclarecer o que o CAP realmente afirma e como ele apareceu na prática durante a competição.
O que o Teorema CAP realmente significa
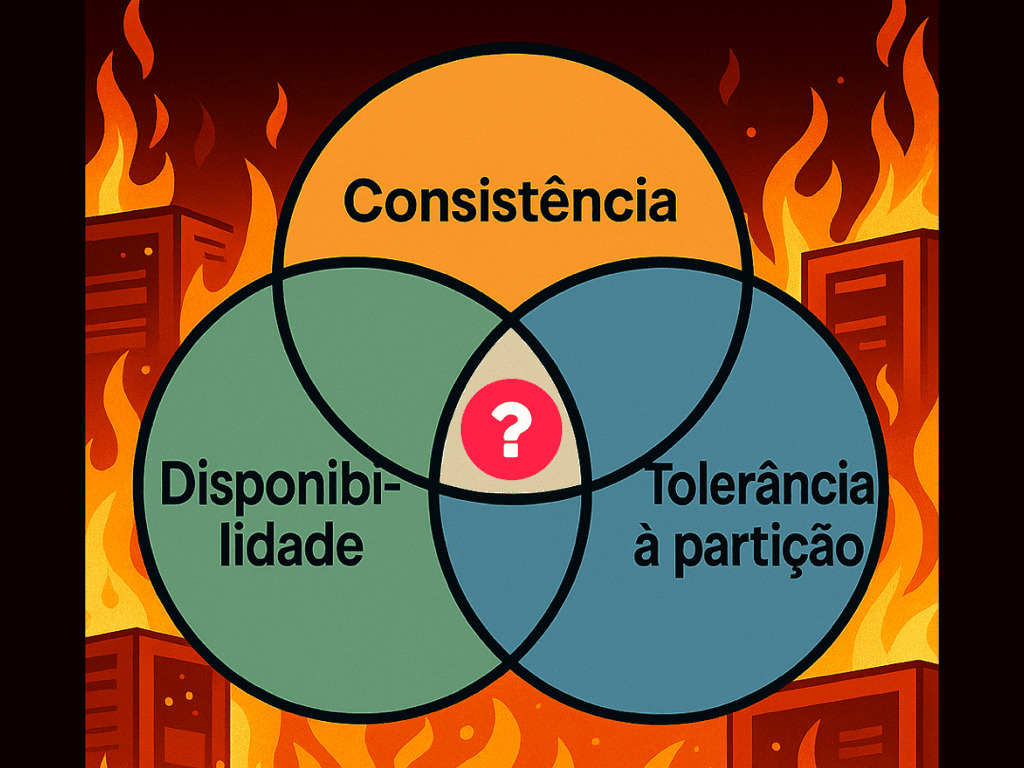
Apresentado por Eric Brewer no início dos anos 2000 e formalizado mais tarde por pesquisadores da computação distribuída, o Teorema CAP define três propriedades que um sistema distribuído não pode garantir ao mesmo tempo em cenários de falha:
- Consistência: todas as partes do sistema refletem os mesmos dados íntegros ao mesmo tempo
- Disponibilidade: o sistema sempre responde a uma solicitação, em qualquer situação
- Tolerância à partição: o sistema continua funcionando mesmo se partes dele não conseguirem se comunicar
Durante uma falha de comunicação (partição), o sistema precisa optar entre duas abordagens: manter consistência e tolerância à partição, abrindo mão da disponibilidade; ou manter disponibilidade e tolerância à partição, abrindo mão da consistência.
Em outras palavras, na presença de partições (falhas de comunicação entre componentes distribuídos que dependem, por exemplo, de rede), é impossível garantir consistência e disponibilidade ao mesmo tempo.
Esses trade-offs são inevitáveis, e o desafio está em decidir qual propriedade priorizar conforme o cenário e as necessidades do sistema.
Como isso aparece na Rinha
Durante a competição, os serviços de pagamento podiam falhar, responder lentamente ou apresentar comportamentos inconsistentes. Isso colocava os participantes diante de escolhas reais sobre como o sistema deveria reagir.
Além disso, havia uma regra explícita no regulamento: qualquer inconsistência no processamento dos pagamentos poderia levar a uma penalidade de 35% sobre a pontuação total. Isso incluía erros como pagamentos duplicados ou valores incorretos. O risco de inconsistência deixava de ser apenas técnico e passava a impactar diretamente o desempenho na competição.
Quem priorizou consistência buscava garantir que as partes do sistema não processassem o mesmo pagamento simultaneamente e que os dados refletissem corretamente o estado mais recente da operação em todas as instâncias. Essa abordagem exigia bloqueios, verificação de estado ou uso de mecanismos de trava. O resultado era maior controle e integridade dos dados, mas menor disponibilidade em momentos de falha.
Outros participantes aceitaram continuar operando mesmo sem confirmação completa do estado atual, priorizando a disponibilidade. Essa estratégia aumentava o throughput, mas também o risco de inconsistências e penalização.
Estratégias observadas na prática
Diversas abordagens foram usadas para lidar com o equilíbrio entre consistência e disponibilidade:
- Filas internas para separar o recebimento do processamento dos pagamentos;
- Processamento assíncrono com reprocessamento de falhas de forma exponencial ou não;
- Replicação entre instâncias para distribuir a carga e manter o estado;
- Uso de travas distribuídas, como a biblioteca ReactiveLock, que foi desenvolvida por mim e utilizada na Rinha para garantir sincronização entre os processos de pagamento e busca das informações;
Cada uma dessas escolhas representava uma posição diferente diante do CAP. Travas e validações garantiam consistência, mas limitavam a capacidade de resposta em momentos de falha. Processamento assíncrono e aceitação otimista priorizavam disponibilidade, mas exigiam mecanismos de compensação e controle posterior.
Além disso, havia os que não utilizavam nenhuma dessas estratégias, optando por soluções mais simples ou sem controle explícito sobre consistência e disponibilidade, o que, em alguns casos, causava inconsistências nos dados, de forma intermitente ou não.
Esse resultado do teste faz parte do processo e nos ajuda a entender, na prática, as consequências das decisões que tomamos. A Rinha de Backend é uma oportunidade para experimentar, ver os impactos reais das escolhas técnicas e, assim, compreender melhor como elas afetam a solução.
No meu caso, escolhi inicialmente chamar apenas a API principal de pagamentos da Rinha de Backend e manter a consistência máxima, implementando a biblioteca ReactiveLock. Essa decisão teve como objetivo provar que, mesmo adotando o caminho mais simples, com alta consistência, é possível ter uma solução. Contudo, em um cenário real, inclusive para o teste da Rinha que definirá o vencedor, essa abordagem não é a ideal, pois depender exclusivamente de uma única API pode causar uma indisponibilidade significativa, prejudicando a execução das operações e penalizando o teste final, que pode ocorrer em condições diferentes do teste prévio que já está acontecendo.
O que aprendemos com isso
O Teorema CAP serve como guia para decisões que só se tornam críticas em momentos de falha. Em cenários normais, é possível manter um bom equilíbrio entre consistência, disponibilidade e tolerância à falha. Mas quando há perda de comunicação, o sistema precisa saber o que sacrificar.
Na prática, a Rinha mostrou que sacrificar consistência pode trazer ganhos de performance, mas também riscos concretos. Quando uma penalidade de 35% está em jogo, aceitar uma operação incerta pode custar muito caro. Ao mesmo tempo, travar o sistema demais para garantir a segurança pode prejudicar o desempenho. Encontrar o equilíbrio foi parte fundamental da estratégia de cada participante.
Conclusão
A Rinha de Backend é mais do que um desafio de velocidade. Ela exige que os participantes tomem decisões técnicas conscientes sobre como lidar com falhas, concorrência e consistência. O Teorema CAP é uma ferramenta útil para orientar essas escolhas. Ele não dita regras, mas ajuda a entender os limites do que é possível em sistemas distribuídos.
Saber quando aceitar uma pequena lentidão para evitar um erro grave ou quando manter o sistema fluindo mesmo com risco de inconsistência é uma habilidade essencial. A competição demonstrou isso com clareza, e os aprendizados servem para muito além do evento.
Referências
- Desafio Rinha de Backend 2025 – Insights e Estratégias com C#, PostgreSQL e ReactiveLock
- The CAP Theorem - Seth Gilbert & Nancy Lynch
- Distributed Systems: Principles and Paradigms - Andrew Tanenbaum
Conecte-se para transformar sua tecnologia!
Saiba mais e entre em contato: